
Summarizing pdf and estimating token count with Amazon Bedrock LLMs

Recently I wanted to use a LLM to summarize a white paper pdf, and stumbled upon this blog post, where the author presents a simple python that accomplishes that task, using ChatGPT API and Gradio as UI. However even though I have a paid ChatGPT subscription, I hit the token limits and wasn’t able to summarize a 19 page pdf.
To address the ChatGPT limitations I was encountering, I decided to use Amazon Bedrock, a LLM-as-a-service offering from AWS, which hosts models from Anthropic, AI21 labs and others.
Before going further, a disclaimer - even though I work for Amazon, the following are my personal opinions and experiments and should not be considered official guidance.
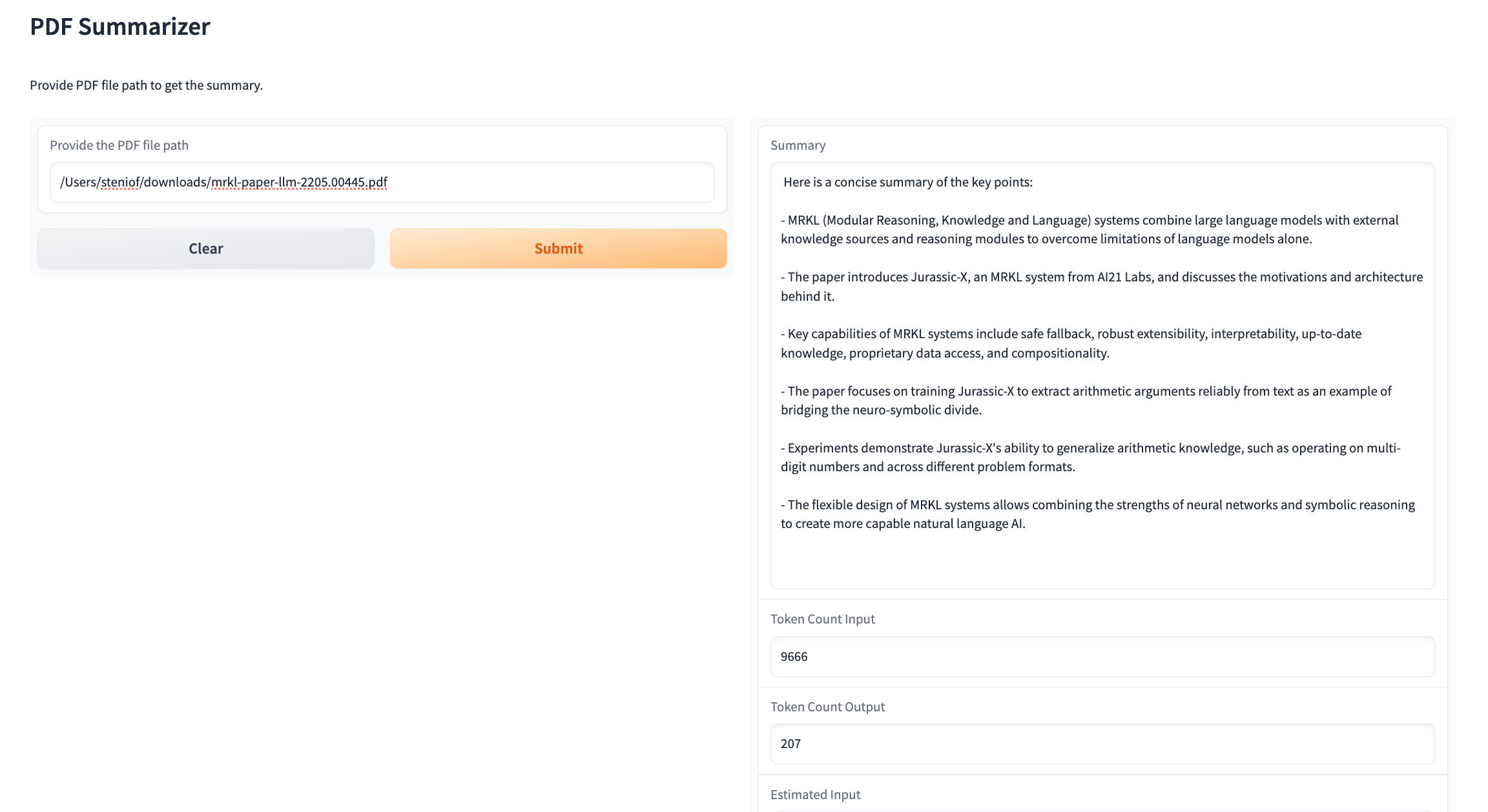
Here is what the UI looks like, the updated code can be found here.
The code itself relies heavily on the original from Naresh, although changing the LLM source from ChatGPT to Bedrock Claude. Having said that, I thought it would be useful to document as a blog because of three main points:
For AWS authentication, I am using AWS CLI profiles, which is a better practice than hardcoding credentials. I also use a conditional, so it allows flexibility should the code be executed from inside a container with environment variables or from an AWS service like ECS
Amazon Bedrock is charged per number of tokens in input and output, so I am using a token counter to get the expected value, as well as an estimation function to compare the real value with the traditional rule of thumb used to estimate number of tokens.
I set Gradio variable launch to False, since I don’t want the app to have public exposure.
As a test, I used this whitepaper about MRKL systems from AI21 labs, And this was the result:
Summary:
Here is a concise summary of the key points:
- MRKL (Modular Reasoning, Knowledge and Language) systems combine large language models with external knowledge sources and reasoning modules to overcome limitations of language models alone.
- The paper introduces Jurassic-X, an MRKL system from AI21 Labs, and discusses the motivations and architecture behind it.
- Key capabilities of MRKL systems include safe fallback, robust extensibility, interpretability, up-to-date knowledge, proprietary data access, and compositionality.
- The paper focuses on training Jurassic-X to extract arithmetic arguments reliably from text as an example of bridging the neuro-symbolic divide.
- Experiments demonstrate Jurassic-X's ability to generalize arithmetic knowledge, such as operating on multi-digit numbers and across different problem formats.
- The flexible design of MRKL systems allows combining the strengths of neural networks and symbolic reasoning to create more capable natural language AI.
Token Count:
Input: 9666
Estimated input: 8978
Output: 207
Estimated output: 250
As can be seen, estimating the number of tokens in a text by counting the number of 4-letter chunks or groups of 4 characters gave a reasonable result in this case. Care should be taken in languages with longer words or special characters.
You can find Amazon Bedrock pricing here. As of December 27th, 2023, the above input/output token usage would cost:
Input: (9666/1000)*0.00800 = $0.08
Output: (207/1000)*0.02400=$0.024
Enjoy!